用朴素贝叶斯辨别文言与白话
自机器学习真正出世,落于实践,已有数年。恰智能科学蓬勃发展之秋,我有幸忝入大数据之专业。近来机器学习开课,授业者不迂腐、同行者有共鸣、学而无倦,实乃幸事。
学习之途,必然会有实践练习与种种思考。我想在此尽力将各类基础模型及其小实践项目记录详实,一来以免遗忘,二来可为偶逢本文之后来者留下些许参考。在下能力有限、造诣浅薄,或并不足出此般豪迈之语,但若有他人从中获益,便是极好之事。
标题或许已经足够概述内容。最近正拜读周志华教授的《机器学习》西瓜书,其序言与正文的字里行间常常表现出先生的文采和深邃思想。或许因此我才想以文言分辨为题,完成贝叶斯分类器的小项目。
本文将从理论和编程的角度分别讲述该实验小项目。至于正态贝叶斯等其他贝叶斯分类器模型,不在本文讨论范围之内。
贝叶斯公式
了解过条件概型的人,大概都知道这样一个简单公式:$P(a|b)=\frac{P(a,b)}{P(b)}$.
用最浅显的语言解释,便是 “在 $b$ 的条件下发生 $a$ 的事件的概率 $P(a|b)$,等于两事件同时发生的概率 $P(a,b)$ 除以 $b$ 事件发生的概率 $P(b)$” 。
这很简单,却也总是会令人遐想——我们是否可以通过这样的一个公式,得到 $P(a|b)$ 与 $P(b|a)$ 之联系,从而达到用现象探寻本质的效果呢?
贝叶斯(Thomas Bayes)或许也这样想过,人们明知好人比坏人更容易做好事,对于偶遇的一个在做好事的人,我们大可推测,此人便是所谓的好人。贝叶斯给出了这样的公式,后来人称其为贝叶斯法则:
其中,$P(y)$被称为 $y$ 的先验概率;而 $P(y|x)$ 由于先有 $x$ 的参与,被称为 $y$ 的后验概率。若把 $x$ 当成做好事的行为,而 $y$ 是“这个人是好人”的结论,我想应该很容易感受到两种概率之间的区别。
我一向认为,单凭一件事情就判定其对象的本质,是一种不够负责且目光短浅的行为。好人应该不单“会做好事”,也会“少做坏事”,更会“避免慷他人之慨”;如果将好人的多个特征都考虑进这个模型中,想必精确度会更高一些。
将上述公式中的 $x$ 用表示多个特征的向量 $\boldsymbol{x}$ 替换,便得到了我们的常用公式:
特征是我们为对象人为选取的几个方面(如对于“西瓜颜色”这一方面,特征值可以是“浅绿色”、“深绿色”、“黄色”等等,只要模型考虑到了该方面的因素)。该式子与上述公式并没有多少不同,仅仅是纳入考虑范围的因素多了一些。
至此,贝叶斯分类器的数学原理也应该大致明晰了,原理并不复杂,正如同真理大多简短。我想用自己的想法做总结——贝叶斯公式,也就是利用多个样本统计出的经验,试图以概率的角度从对象的特征判断其本质。
贝叶斯公式细节:不同的贝叶斯分类器
我们再仔细观察上述公式中每一项(为方便后续讲述,我将 $y$ 用代表任一类别的 $c$ 替换):
其中 $P(\boldsymbol{x})$ 对于不同的 $c$ 总是相同的,鉴于我们的任务是将 $\boldsymbol{x}$ 分类,需要对不同的类别的概率 $P(c|\boldsymbol{x})$ 进行比较,故可以直接忽视,等到比较时略去即可。
$P(c)$ 是所谓类概率,课本言:“$P(c)$ 为 $c$ 类别的样本在训练集中出现的概率,即 $P(c) = \frac{N_c}{N}$.”,但我认为并不够妥当。多数情况,我们并不能通过样本比例来判断实际情况中的类别比例,也就是说,我们选取的样本并不一定与事实和应用场景中的类别比例相同。我认为,这个值可以作为超参数由使用者人为提供,以达到最好的效果。
然后是最为复杂的 $P(\boldsymbol{x}|c)$ ,$\boldsymbol{x}$ 包含了我们选取的要判断的对象所拥有的特征,其分量个数可称为维数;如何将其化简成我们能够简单计算的式子,便是多数贝叶斯分类器的不同之处——如果我们认定其中特征有所联系,因此在展开时考虑入协方差,如果我们人为认定每一特征最多与 $k$ 个特征有联系,便成了半朴素贝叶斯分类器;如果我们认定特征都是连续的,并且都满足正态分布,并用均值和方差展开,便成了正态贝叶斯分类器。最最特殊且平常的一种想法,我们认定每种特征都独立,不依附其他特征存在,直接用条件独立公式展开,便成了朴素贝叶斯分类器。
下面我将通过项目中的例子来具体阐述。
朴素贝叶斯,并加之自然语言
公式化简
我所做的练习项目是分辨自然语言的文言与白话,分析的对象便是自然语言的句子,特征可以选取“某些词语出现的频率”,而本项目中,我选择的是 “分词是否出现”。
对于例句“我永远喜欢有马加奈”,人们一般分词为’我’,’永远’,’喜欢’,’有马加奈’。而放入公式中,则是:
我们选用朴素贝叶斯分类器,假设各条件独立,根据条件独立公式展开可以得到:
其中 $P(“词语”|c)$ 是在我们训练的模型中,出现过“词语”一词的句子频率(这是因为我选择的特征是“分词是否出现”,切记自己选择的特征的含义)。用“我”字举例,则是:$P(“我”|c)=\frac{N_c(“我”)}{N_c}$ 。比起之前的公式,上式显然更好求值。
和西瓜书的练习题不同,自然语言有更多的可能性,想要提高识别精度自然需要更多的训练样本,单单是我做的小模型,文言与白话分别都使用了 $100000$ 个句子进行训练(选择同样多的训练集也有其用意,详见下文;训练集请参见本文末),因此,每一个分词所得到的概率,都是一个极小的小数,若要相乘起来,更是要求极高的小数精度最终还要比较两种类别的概率浮点数大小,很明显不是一个明智的做法。
我对公式再次进行变形:
则对于任一类别 $c$ ,我们只需要比较上式中不同的部分即可。也就是说,我们仅需要比较每个类别用下式得到的计算值:
当每个类别的训练样本相同多的时候,$N_c$ 也将相同,如我的模型中则为 $100000$ ;而前文提到,我认为 $P(c)$ 可以人为取值,这里我为文言和白话两个类别都取为0.5(但就算根据样本之比的定义来取值,这里也应该是0.5)。进一步化简,可得结果类别为:
其中 $\underset{c}{\arg\max}$ 表示整个式子的结果为令后面式子值最大的 $c$ 的值。整个式子已经变成了十分简单的形式,对于部分语言的实现,我们仅需考虑大数的溢出问题,相比小数的溢出已是十分简单。
拉普拉斯平滑
中文分词基本不可能穷举,显然,样本并不可能涵盖所有词语,句子中各个分词的频数并不一定不为0.在例句中,“有马加奈”一词便不一定存在于模型中,如果任由其为0,则式子计算值为0.
在机器学习中有一种名为拉普拉斯平滑的数据处理方式,我们为每个特征的频数都加 $1$,样本总数都加$k$($k$ 为该特征的可能情况数,如本例只有“有”和“没有”两种状态,则$k=2$),这样各种情况的概率和仍然为 $1$。对于上述例句,则有 $P(“我”|c)=\frac{N_c(“我”)+1}{N_c+2}$ ,便可避免计算值归零的错误。
接下来便是用程序实现这个分类算法了。
程序实现
我们需要先准备数据集。这期间,我本想用小爬虫从古诗文网自动爬取古诗文,但可惜其数据并未分句,还带有作者、标题等内容,而后我找来长篇的古文经书电子档,却也有许多难以去除的广告内容和不规范的格式。分句尚可用句号来分割,但不干净的数据却会影响程序的训练效果。最终,我在 Github 找到了一个古文对应翻译的数据集仓库。
中文分词我使用了 Python 的 jiaba 库,这是最方便的做法。
接下来是贴代码时间,完整程序加上模型和测试结果可在我的这个仓库中看到,以下代码可以直接略过。
然后我写了简单的训练程序:
# train.py
'''利用训练集进行训练'''
from pathlib import Path
from collections import Counter
from dataclasses import dataclass, field
from utils import check_file # 这是小工具,检查文件是否存在
import jieba
import json
from config import * # 这里是我提供可设置项的文件
@dataclass
class Category:
name:str
cnt:int = 0
data:dict[str, int] = field(default_factory=Counter)
def new_sentence(self, words:set[str]):
'''增加新句子的特征'''
self.cnt += 1
self.data += Counter(words)
def to_dic(self) -> dict:
'''转化为字典'''
return {
"count": self.cnt,
"data": self.data
}
def save_model(self, file_path:Path):
'''将Category模型保存为json文件'''
check_file(file_path)
with open(file_path, "w", encoding="UTF-8-sig") as f:
json.dump(self.to_dic(), f)
print(f"类别 {self.name} 的统计模型已保存。")
def statistic(path:Path, name:str = '', result:Category=None, max_count = 0):
'''对目标训练文本目录进行递归统计,并保存结果'''
if not result:
result = Category(name)
for sub in path.iterdir():
if sub.is_file():
with open(sub, "r", encoding="UTF-8-sig") as f:
while (sentence := f.readline()) and (max_count and result.cnt < max_count):
words = set(jieba.cut(sentence, cut_all=True))
result.new_sentence(words)
else:
statistic(path, result=result, max_count=max_count)
save_path = model_path / f"{name}.category"
result.save_model(save_path)
if __name__ == '__main__':
for category in categories_info:
statistic(category["path"], category["name"], max_count=max_count)
print("所有标签已训练完成~")
得到了模型,文言的模型大概长这样:
然后是利用模型进行分类的程序(其中使用了拉普拉斯平滑):
# bayes.py
'''利用朴素贝叶斯进行文言白话的判断'''
import json
import jieba
from config import *
from utils import mul
def get_words_count(words:set[str], category_name:str) -> tuple[int]:
'''获得各个分词在所指类别模型中的频数'''
category_path = model_path / (category_name+".category")
if not category_path.is_file():
raise Exception(f"找不到目标路径 {category_path}")
with open(category_path, "r", encoding="UTF-8-sig") as f:
category_data:dict = json.load(f)
return ((category_data["data"].get(word, 0)+1) for word in words if word not in punctuation) #进行了拉普拉斯平滑
def bayes(sentence:str, logger=True) -> int:
'''
利用贝叶斯分类器进行分类
:rtype: 返回分类结果,-1为白话,0为无法区分,1为文言
'''
words = set(jieba.cut(sentence, cut_all=True))
categories_res = []
for category in categories_info:
cnt = get_words_count(words, category["name"])
res = mul(cnt)
if logger: print(f"类别【{category['name_cn']}】公式计算值得 {res}")
categories_res.append((res, category["name"], category["name_cn"]))
if logger: print("=========")
if (1/res_retio) < (categories_res[1][0] / categories_res[0][0]) < res_retio:
if logger: print("该句子无法分辨出文言或白话")
return 0
else:
final_res = max(categories_res)
if logger: print(f"该句子分类为【{final_res[2]}】")
for category in categories_info:
if category["name"] == final_res[1]:
if category["rflag"]:
return category["rflag"]
else:
raise Exception(f"类别 {category['name']} 的返回值不能设置为 0.")
if __name__ == '__main__':
sentence = " 晋太元中,武陵人捕鱼为业。缘溪行,忘路之远近。忽逢桃花林,夹岸数百步,中无杂树,芳草鲜美,落英缤纷。渔人甚异之,复前行,欲穷其林。 "
bayes(sentence)
由于已知只有两个类别,我们可以直接比较两类别的计算值得出结论,同时我还设置了一个结果为“无法区分”的区间,可以避免很多语句的误分类。
这时候可以利用程序简单看看效果了


如果要更科学的看到效果,我们还要准备测试集,自己分句也可,从未使用的训练集截取也行(由于是简单程序,并没有用交叉验证等等方法)。然后是测试程序:
'''利用测试集进行判定'''
from config import *
from bayes import bayes
from pathlib import Path
def single_test(category_name:str, flag:int, logger=True):
'''
对目标测试集进行分类测试
:param flag: 正确的分类器返回值
:param logger: 是否在控制台输出分类失败和分类错误的句子
'''
test_file = test_path / f"{category_name}.test"
if not test_file.is_file():
raise Exception(f"找不到目标文件 {test_file}")
total_cnt, correct_cnt, unkown_cnt = 0,0,0
false_sentence, unkown_sentence = [],[]
with open(test_file, "r", encoding="UTF-8-sig") as f:
while sentence := f.readline():
result = bayes(sentence, False)
total_cnt += 1
if not result:
unkown_sentence.append("【分类失败】"+sentence)
unkown_cnt += 1
elif result == flag:
correct_cnt += 1
else:
false_sentence.append("【分类错误】"+sentence)
false_sentence = '\n'.join(false_sentence)
unkown_sentence = '\n'.join(unkown_sentence)
if logger:
print(false_sentence)
print(unkown_sentence)
result = (
"=========\n"
f"类别【{category_name}】测试结果:\n"
f"测试总数:{total_cnt}\n"
f"正确数:{correct_cnt}\n"
f"分类失败数:{unkown_cnt}\n"
f"正确率:{correct_cnt/(total_cnt-unkown_cnt):.2%} (已去除分类失败数)\n"
f"错误率:{(total_cnt-unkown_cnt-correct_cnt)/(total_cnt-unkown_cnt):.2%} (已去除分类失败数)\n"
"=========\n"
f"分类器 res_retio 值为 {res_retio}\n"
"=========\n"
)
print(result)
with open(test_path / f"{category_name}.result", "w", encoding="UTF-8-sig") as f:
f.write(result)
f.write(false_sentence)
f.write(unkown_sentence)
def global_test(logger=True):
'''对config中所提所有类别进行分类测试'''
for category in categories_info:
single_test(category["name"], category["rflag"], logger=logger)
if __name__ == "__main__":
global_test(False)
测试效果:
在课程汇报前多添加了几个小指标,都接近于1,效果还算不错。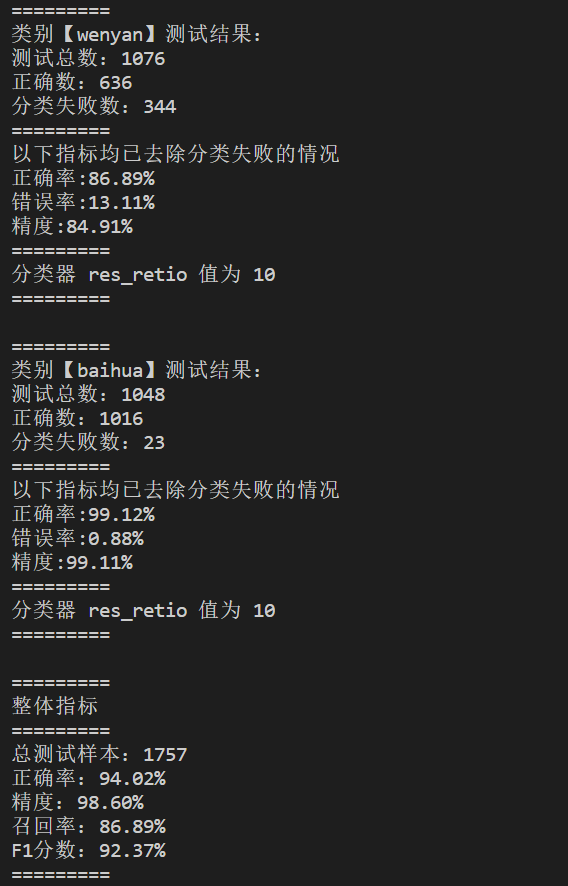
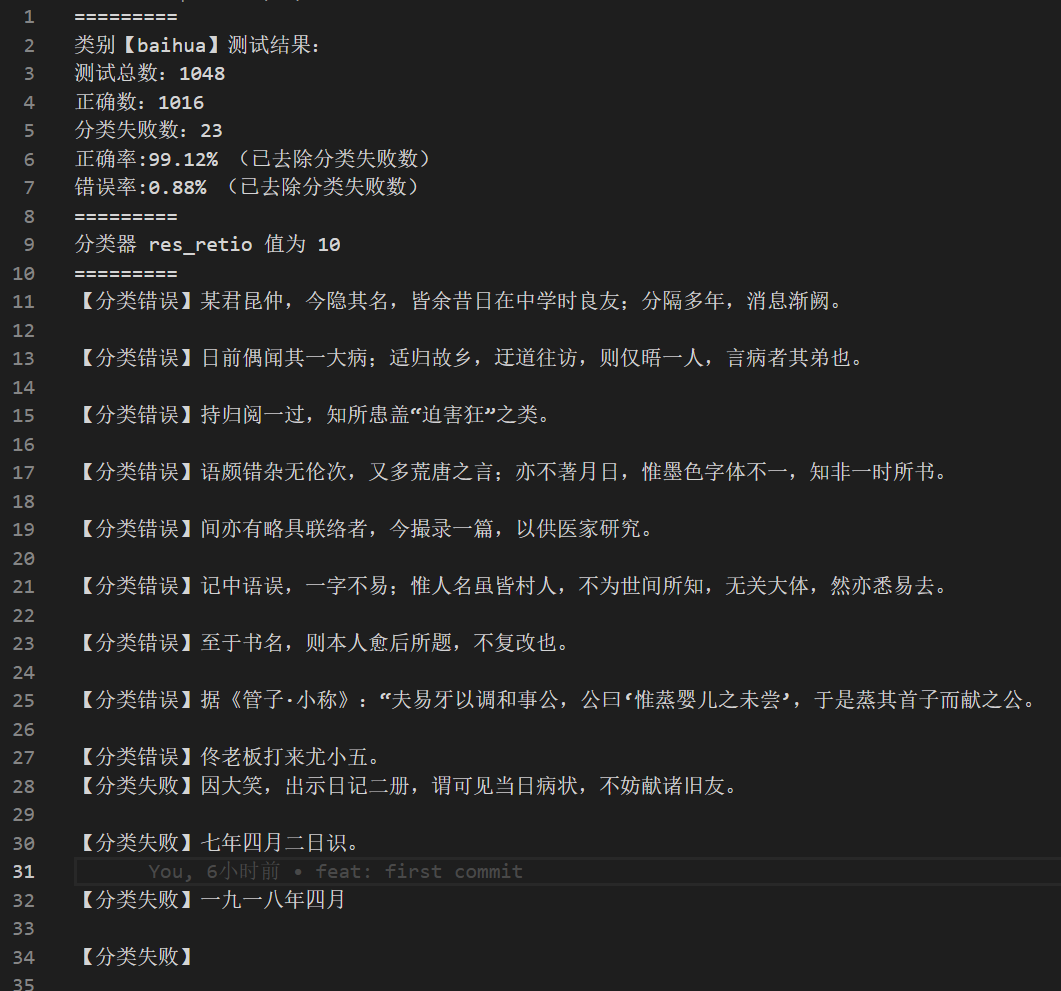
白话识别效果较好,识别错误的基本都为鲁迅先生写的文言。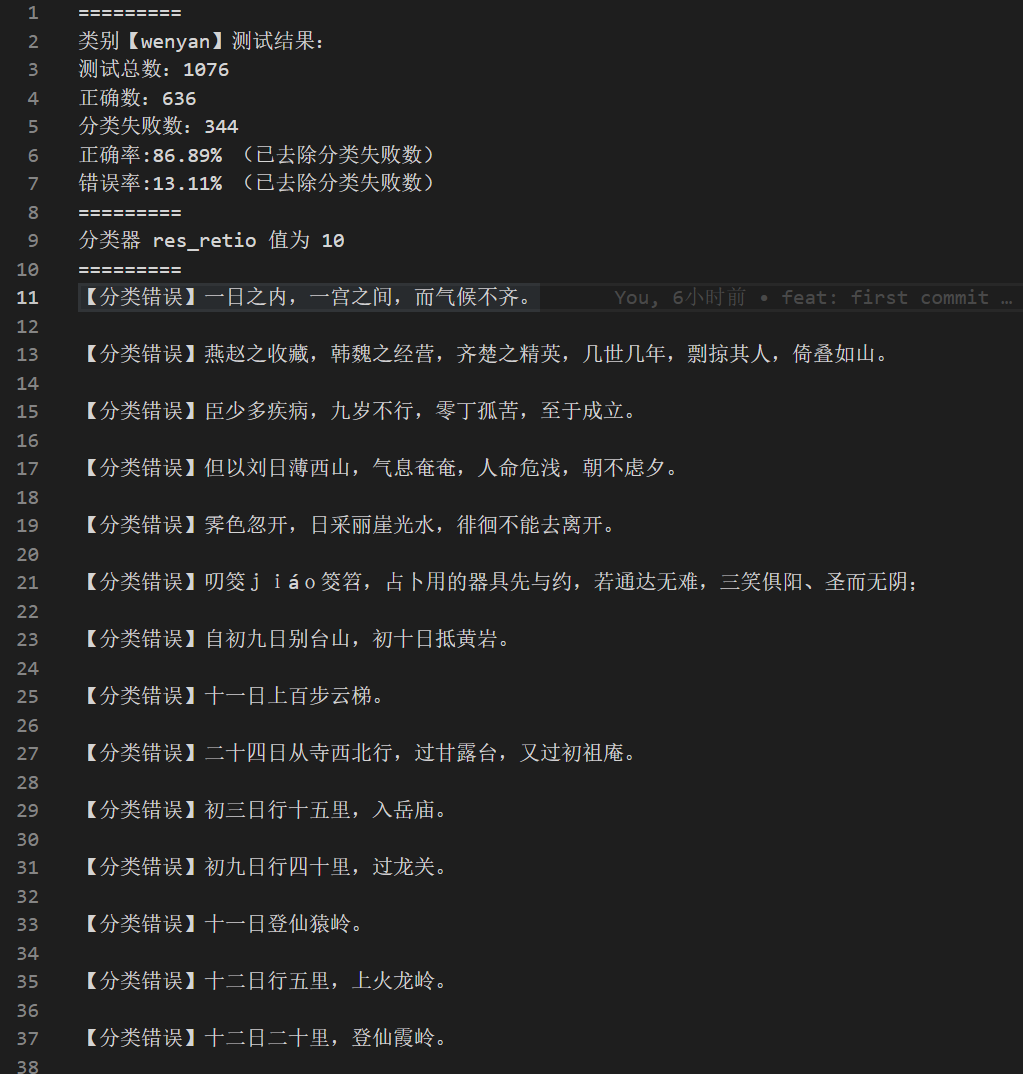
文言或许是因为词语更多,训练 $100000$ 句也不甚足够,但正确率也足够高了。
程序大概就如此,具体细节请参考我的这个仓库。
注意事项
- 对于上述例句,jieba 分词全分词可得到[‘我’,’永远’,’喜欢’,’有’,’马’,’加’,’奈’]。对于专有名词被误分解的情况,如果是在特殊应用场景,我认为要在训练集中就考虑到该情况,而一般情况下只有尽力避免对此类例句进行分析,或者人为用非中文字符代替。
- 对于标点符号,我并没有在训练时进行清除,而是在测试时忽略它们,毕竟对众多样本句子都进行清洗显然效率更低。
- 不在忽略名单中的生僻字、乱码等,可以预见其在白话和文言中的频数均为 $0$ ,在平滑处理后他们都会变成对结果不会有影响的 $1$,不妨不加考虑。
- 同学者在测试本项目时,大多提到“如果给予一串无意义的句子,如‘啊说从嗄有分或吧’,却仍然会分辨白话文言”,我想回应的是,这个练手项目的目的仅仅是分辨文言和白话,而非分辨语句有无意义,这并不是一个关键问题。
本文内容仅仅是机器学习入门知识,或不够全面,也或有纰漏之处,望来者不吝指教;作文不足之处还望海涵。